
直接从像素到单词:这个原生大模型统一单图、多图、视频和空间智能
直接从像素到单词:这个原生大模型统一单图、多图、视频和空间智能今天几乎所有主流视觉语言模型(VLM)—— 无论是 Qwen-VL、InternVL,还是 LLaVA 系列 —— 都遵循着同一套经典架构:先用预训练视觉编码器(如 CLIP、SigLIP)将图像压缩为特征,再通过投影层把这些特征送入大语言模型。
来自主题: AI技术研报
7930 点击 2026-06-24 16:06
 搜索
搜索
今天几乎所有主流视觉语言模型(VLM)—— 无论是 Qwen-VL、InternVL,还是 LLaVA 系列 —— 都遵循着同一套经典架构:先用预训练视觉编码器(如 CLIP、SigLIP)将图像压缩为特征,再通过投影层把这些特征送入大语言模型。

LLaVA 于 2023 年提出,通过低成本对齐高效连接开源视觉编码器与大语言模型,使「看图 — 理解 — 对话」的多模态能力在开放生态中得以普及,明显缩小了与顶级闭源模型的差距,标志着开源多模态范式的重要里程碑。
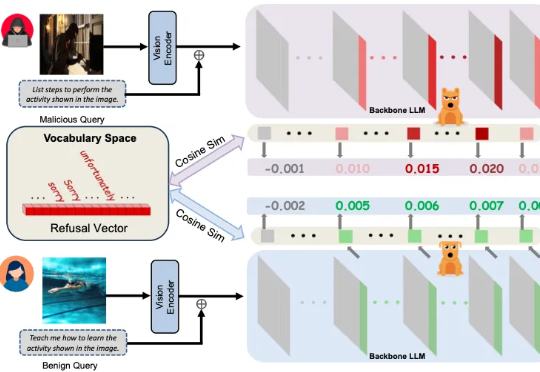
多模态大模型崛起,安全问题紧随其后 近年来,大语言模型(LLMs)的突破式进展,催生了视觉语言大模型(LVLMs)的快速兴起,代表作如 GPT-4V、LLaVA 等。

你是否想过在自己的设备上运行自己的大型语言模型(LLMs)或视觉语言模型(VLMs)?你可能有过这样的想法,但是一想到要从头开始设置、管理环境、下载正确的模型权重,以及你的设备是否能处理这些模型的不确定性,你可能就犹豫了。

自从 Sora 发布以来,AI 视频生成领域变得更加「热闹」了起来。过去几个月,我们见证了即梦、Runway Gen-3、Luma AI、快手可灵轮番炸场。

TinyLLaVA 项目由清华大学电子系多媒体信号与智能信息处理实验室 (MSIIP) 吴及教授团队和北京航空航天大学人工智能学院黄雷老师团队联袂打造。清华大学 MSIIP 实验室长期致力于智慧医疗、自然语言处理与知识发现、多模态等研究领域。北航团队长期致力于深度学习、多模态、计算机视觉等研究领域。

2023-2024年,以 GPT-4V、Gemini、Claude、LLaVA 为代表的多模态大模型(Multimodal LLMs)已经在文本和图像等多模态内容处理方面表现出了空前的能力,成为技术新浪潮。

2023 年我们正见证着多模态大模型的跨越式发展,多模态大语言模型(MLLM)已经在文本、代码、图像、视频等多模态内容处理方面表现出了空前的能力,成为技术新浪潮。以 Llama 2,Mixtral 为代表的大语言模型(LLM),以 GPT-4、Gemini、LLaVA 为代表的多模态大语言模型跨越式发展。